McCall Search Model
2026-04-20
The Decision Tree
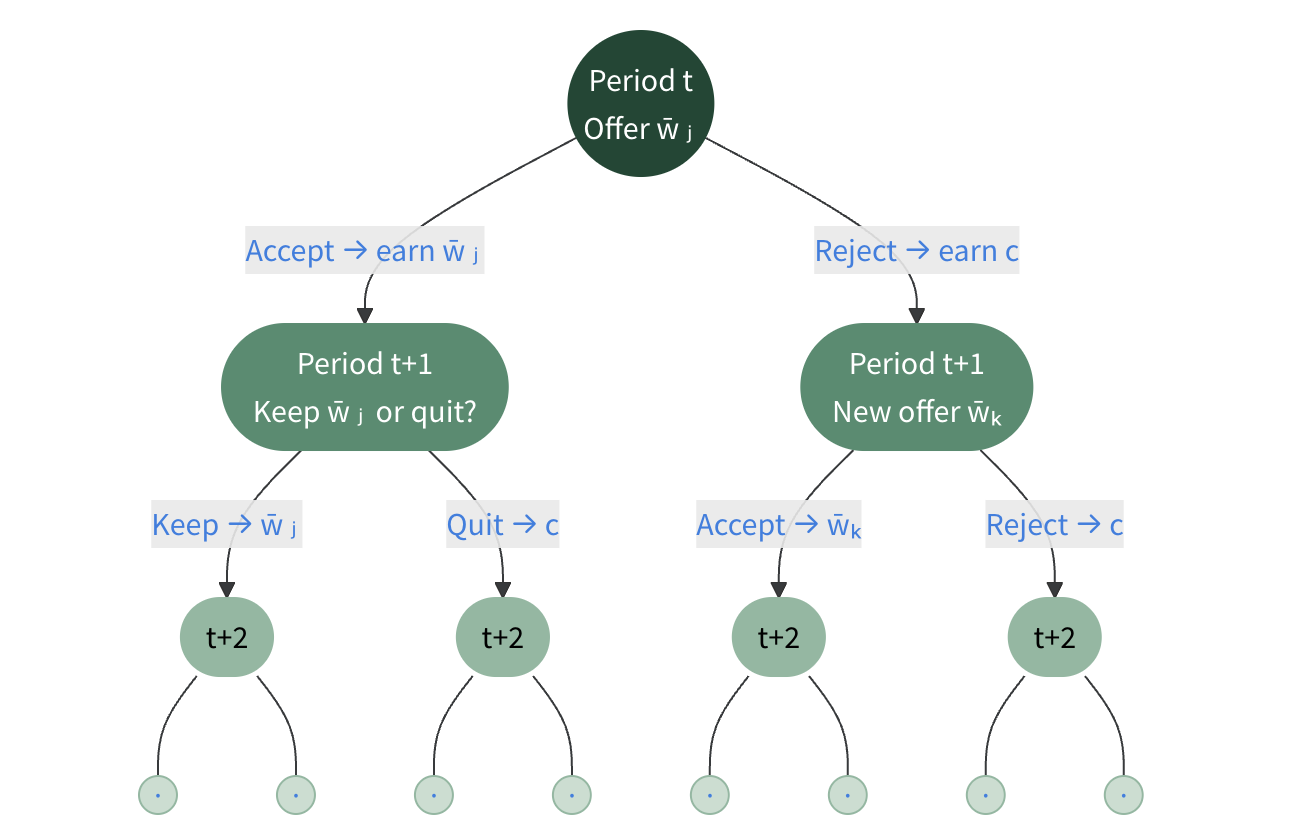
- \(2^n\) possible paths after \(n\) periods — how to solve this efficiently?
Plotting the One-Period Value

Plotting the Two-Period Value

Plotting Value Functions

- More periods left \(\rightarrow\) higher value (more opportunities to find a good wage)
Value Functions for 100 Periods

- Note: little difference between \(V_{50}\) and \(V_{100}\) — the value function is converging
The Infinite Horizon Solution

The Optimal Policy

Using the Struct Version
Hazard Rate and Unemployment Benefits
- How does the hazard rate change with \(c\)?
cvalues = LinRange(0, 5, 100) # grid of c values to try
hvalues = zeros(length(cvalues)) # store hazard rate for each c
for i in 1:length(cvalues) # loop over each c
sol = solveMcCall(McCallModel(c=cvalues[i])) # create model, solve
hvalues[i] = dot(p, sol.C) # compute hazard rate p⋅C
end
plot(cvalues, hvalues, linewidth=2, label="Hazard Rate", legend=:topright)
xlabel!("Unemployment Benefits (c)") # label axes
ylabel!("Hazard Rate")
- Higher \(c\) \(\rightarrow\) worker is more selective \(\rightarrow\) lower hazard rate
Effect of Firing Probability (\(\alpha\))

- Higher firing risk \(\rightarrow\) lower value of employment \(\rightarrow\) lower value overall
Effect of Unemployment Benefits (\(c\))

What is a Mean Preserving Spread?
- A change in the wage distribution that keeps the mean the same but increases the variance

Effect on Value and Policy

Effect on Acceptance Policy
